-
코로나 신규확진자, 일일검사자, 월별 확진자 통계카테고리 없음 2021. 1. 14. 16:44반응형
새해들어 날씨가 급격히 추워져서 그런지
정부의 거리두기가 성공적이었는지
확진자 수가 줄어들고 있습니다.
그래서 신규확진자 및
검사인원 분석을 해보겠습니다 !!
먼저 공공데이터 api_key 를 준비해주세요 !!
여기서 발급
https://www.data.go.kr/tcs/dss/selectApiDataDetailView.do?publicDataPk=15043376
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Dataset)와 Open API로 제공하는 사이트입니다.
www.data.go.kr
데이터를 조회 할 때는 시작일, 종료일 두가지가 필요합니다.
제가 짠 코드에서는 조회일을 종료일로 기준을 두고
시작 일은 timedelta를 이용해서 380일 전까지 로 해서 시작일을 만들어 냈습니다.
시작일 종료일을 직접 입력해서 조회할 수도 있겠죠?
from urllib.request import urlopen from urllib.parse import urlencode, unquote, quote_plus import urllib import requests import json import pandas as pd from datetime import datetime,timedelta yester = datetime.today() - timedelta(380) yseter = yester.strftime("%Y%m%d") now_today = datetime.today() - timedelta(0) now_today = now_today.strftime("%Y%m%d") print(yseter) print(now_today) my_api_key = '__api_key__' url = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19InfStateJson' queryParams = '?' + \ 'ServiceKey=' + '{}'.format(my_api_key) + \ '&pageNo='+ '1' + \ '&numOfRows='+ '999' + \ '&startCreateDt={}&endCreateDt={}'.format(yseter,now_today)
조회 결과가 xml 형태되있습니다.
그래서 json형태로 바꿨고 영문으로 되어있는 컬럼명을 한글로 변경했습니다.(공공데이터 api사용설명 doc 참조)
import xmltodict result = requests.get(url + queryParams) # print(result) result = result.content jsonString = json.dumps(xmltodict.parse(result), indent = 4) jsonString = jsonString.replace('resultCode', '결과코드').replace('resultMsg', '결과메세지').replace('numOfRows', '한 페이지 결과 수').replace('pageNo', '페이지 수').replace('totalCount', '전체 결과 수').replace('seq', '게시글번호(감염현황 고유값)').replace('stateDt', '기준일').replace('stateTime', '기준시간').replace('decideCnt', '누적 확진자 수').replace('clearCnt', '격리해제 수').replace('examCnt', '검사진행 수').replace('deathCnt', '누적 사망자 수').replace('careCnt', '치료중 환자 수').replace('resutlNegCnt', '결과 음성 수').replace('accExamCnt', '누적 검사 수').replace('accExamCompCnt', '누적 검사 완료 수').replace('accDefRate', '누적 확진률').replace('createDt', '등록일시분초').replace('updateDt', '수정일시분초') js = json.loads(jsonString) # print(js) js_check_count = js["response"]['body']['items']['item'][0]['검사진행 수'] js = js["response"]['body']['items']['item'] all_data = pd.DataFrame(js)
이중에서 사용할 정보만 select_data에 저장하고
Nan 값의 데이터는 0으로 치환했습니다.( DataFrame.fillna(0))
또 sort_values를 이용해서 "기준일"을 기준으로 정렬했습니다.
select_data = all_data[['기준일','누적 사망자 수','누적 검사 수', '누적 확진자 수']] # nan 값을 0으로 치환 select_data = select_data.fillna(0) select_data.sort_values(by = '기준일', inplace = True, ascending = True) select_data = select_data.reset_index(drop = True) select_data
데이터의 수정 변경으로 인해
하나의 날짜에 두개 이상 데이터가 있어 groupby함수를 사용해서
하나의 날짜에 하나의 데이터가 있도록 집계하였습니다.
그 전에 누적 확진자 수는 to_numeric을 사용하여 데이터의 numeric으로 변경하였고
기준일은 to_datetime을 사용하여 datetime으로 변경했습니다.
select_data['누적 확진자 수'] = pd.to_numeric(select_data['누적 확진자 수']) select_data['기준일'] = pd.to_datetime(select_data['기준일']) # groupby를 사용하여 집계를 할 때 기준 연산을 설정.. f = {'누적 확진자 수':'min','누적 검사 수':'max','누적 사망자 수':'max'} # 기준일을 기준으로 집계 data1 = select_data.groupby('기준일').agg(f) # 기준일을 기준으로 정렬 data1.sort_values(by = '기준일', inplace=True, ascending = True) pdata = data1.reset_index(drop = False) pdata.columns = ['기준일', '누적 확진자 수', '누적 검사 수', '누적 사망자 수'] pdata
일일 확진자 수, 일일 검사자 수 데이터가 존재하지 않아
전일과 누적수의 차이로 계산했습니다.
데이터가 뒤죽박죽인 경우가 있어서 먼저 큰수에서 작은 수를 빼는
함수를 정의하여 재사용성을 높였습니다.
def compare_sub(a,b): if a > b : c = a-b return c else : c = b-a return c
def compare_sub(a,b): if a > b : c = a-b return c else : c = b-a return c
위의 정이한 compare_sub 함수를 사용하여
일일 확진자 수와 일일 검사 수를 pdata에 추가합니다.
daily_crn_cnt = [] daily_check_cnt = [] for row in range(0,len(pdata['누적 확진자 수'])-1): daily_crn_cnt.append(compare_sub(int(pdata.loc[row+1][1]), int(pdata.loc[row][1]))) # print(pdata['기준일'][row],',',int(pdata.loc[row+1][1]) ,'-', int(pdata.loc[row][1]) ,'=', compare_sub(int(pdata.loc[row+1][1]), int(pdata.loc[row][1]))) daily_check_cnt.append(compare_sub(int(pdata.loc[row+1][2]),int(pdata.loc[row][2]))) # print(pdata['기준일'][row],',',int(pdata.loc[row+1][2]),'-',int(pdata.loc[row][2]), '=', compare_sub(int(pdata.loc[row+1][2]),int(pdata.loc[row][2]))) pdata = pdata.drop(1) pdata['일일 확진자 수'] = daily_crn_cnt pdata['일일 검사 수'] = daily_check_cnt pdata['일일 검사 수'] = pd.to_numeric(pdata["일일 검사 수"]) pdata['누적 사망자 수'] = pd.to_numeric(pdata['누적 사망자 수'])마지막 ! 그래프로 출력하기
일일 검사 수 에서 3월초 데이터에 이전에 집계되지 않았던 데이터가
한번에 들어가 있어서 데이터 표출결과에 대한 오해가 있을수 있기 때문에 제거했습니다.
(pdata = pdata[pdata["일일 검사 수"] <100000])
import matplotlib.pyplot as plt import numpy as np ## 3월 초에 집계가 시작되어 이전 검사수를 모두 더한 데이터가 api상에 저장되있어 ## 그래프 표출시 오해의 소지가 있기 때문에 제거. print(pdata.keys()) pdata = pdata[pdata["일일 검사 수"] <100000] for a in pdata.keys(): if a != '기준일': plt.style.use('seaborn-whitegrid') plt.figure(figsize=(29,9)) plt.plot(pdata['기준일'],pdata[a]) plt.show()누적 확진자 수

누적 검사자 수(10만 단위)

누적 사망자 수

12월은 날씨도 춥고 확진자 수도증가함에 따라
누적 사망자수의 그래프의 기울기가 가파른것을 볼수있습니다 ㅠ
일일 확진자 수

피크를 찍고 다시 줄어들고 있는 추세입니다.
마치 주식 그래프를 보는듯한.....
떡락해라 !!! 코로나 그래프야 !!!!!!!!!!!!!!!!!!!

일일 검사자 수
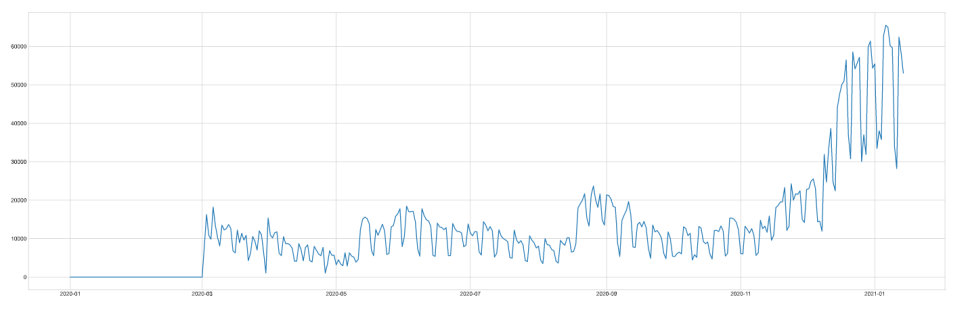
검사자 수는 크게 감소하지 않았는데
확진자 수가 줄어들고 있어서 다행인것 같습니다.
데이터는 발표한 일자를 기준으로 집계했습니다.
ex ) 12/30 일 00시00분 집계 >>>> 12/30일 발표한 검사 수, 확진자 수
전체 데이터 및 설명은 깃허브를 참조해주세요 !!
https://github.com/ziwon-seo/corona_api_ana.git
ziwon-seo/corona_api_ana
Contribute to ziwon-seo/corona_api_ana development by creating an account on GitHub.
github.com
그럼 코로나의 떡락을 기대하며 !!

모두 건강조심하시고
마스크 착용잘 하셔요 (요즘 마스크를 너무 잘 써서 감기 환자가 줄었다고 하네요 ㅋㅋㅋ)
댓글과 공감은 사랑입니다 !!!
반응형